We traveled to Toronto this year to attend RWC 2024. The conference was held in TIFF Lightbox located in the city’s downtown; the venue is the headquarters for the Toronto Film Festival and contains five cinema rooms. RWC is a single-tracked conference and there’s no hard requirement that talks are backed by papers. Each RWC includes the Levchin prize ceremony for major achievements in applied cryptography, several invited talks and the lightning talks session.
Apart from one cinema with the live conference talks, another room was made available to folks who were ready to trade the in-person presentations for video streamed talks to get more room, which was super-nice.

In this blog post, we share our notes on several sections of the conference. We hope to capture some of the cryptographic development trends in areas such as post-quantum messaging, key transparency and privacy enhancing technologies. Not all papers are covered, but for those that are, we put more emphasis on the general context in which these technologies appear than the specific details.
Key transparency
Written by: Filippo Valsorda
Certificate Transparency, the original design of transparency logs applied to X.509 certificates for the WebPKI (the ones used by browsers for HTTPS), won the Levchin Prize (award ceremony recording).
The Levchin Prize is awarded every year to two “major innovations in cryptography that have had a significant impact on the practice of cryptography and its use in real-world systems”. CT certainly fits the bill; the other Levchin prize was awarded for work on anonymous credentials (more on that later on).
From the prize announcement:
Certificate Transparency was a response to the 2011 attack on DigiNotar and other Certificate Authorities. These attacks showed that the lack of transparency in the way CAs operate was a significant risk to the Web Public Key Infrastructure (PKI). It led to the creation of the Certificate Transparency project to improve Internet security by bringing accountability to the system that protects HTTPS. Since 2013, the Certificate Transparency community has effectively monitored and fixed certificate anomalies. The award recognizes the enormous effort that it took to make Certificate Transparency a reality on the Web, and the tangible security benefits that it brings to all Web users.
Aside from the prize, there were three transparency logging talks plus some mentions in other talks: one about tlogs in general by me, and two about key transparency.
Modern transparency logs
CT introduced the concept of transparency logs, but also had to apply it to an incredibly complex setting: the existing Certificate Authority ecosystem. That led to a design that mixes fundamental aspects of what a tlog is with specific affordances for the CT setting, which made the design less reusable.
There’s an arc to new technologies: first we try a new thing, then we learn how to do it right, then we learn how to abstract it so it’s reusable without learning how to do it right. In my talk, I try to present some of what we learned in the past ten years, and the abstractions that I think we can start building.
At their core, I present tlogs as magic append-only lists of entries with a global view. These lists are defined by application-specific answers to questions such as “What are the entries?”, “Who can add entries?” and “Who monitors entries?”. For example, the Go Checksum Database is a tlog where the entries are the hashes of Go module versions, added by Google, and monitored by Go module publishers to make sure they match what they intended.
What tlogs are for is for staking reputation on accountable claims: for example, with the Go Checksum Database Google is staking its reputation on the Go modules source it claims to have fetched from, for example, GitHub.
In the rest of the talk I present some of the components and deployment techniques necessary to service that abstraction, including the witness ecosystem being worked on together with Google and Sigsum.
Finally, I present my favorite abstraction for applying tlogs to existing systems: as a “spicy” signature algorithm. Just like signing something with a digital signature algorithm produces a signature that can be verified with a public key, adding an entry to a tlog produces a “spicy signature” (the combination of log index, inclusion proof, signed tree head, and witness co-signatures) that can be verified offline with the log and witnesses public keys. Spicy signatures provide a tool that fits many common deployment settings, and I demonstrate how easy they are to use with a short PoC that applies tlogs to the Debian APT repositories.
“WhatsApp key transparency” and “Key transparency: introduction, recent results, and open problems”
WhatsApp Key Transparency: slides, video.
Key transparency: introduction, recent results, and open problems: slides, video.
The other two talks are about key transparency: transparency logs applied to mapping users/phone numbers to their public key. KT is a critical piece of secure and usable end-to-end encryption in messaging, as it prevents MitM attacks by faking keys without requiring users to compare “safety codes” which almost nobody does anyway.
Hypothetically, you could apply a simple tlog to this: just make a list where the entries are {phone number, public key} like the Go Checksum Database is a list of entries {module, version, hash}. Two problems with that: unlike Go modules hashes the public key associated with a phone number can change; and you don’t want to leak a list of all phone numbers that use WhatsApp.
You could just allow multiple entries for the list under one phone number, but then how does a client know it’s not being shown an old key? CONIKS solves that with sparse Merkle Trees: the bits of the hash of the phone number identify a position in the tree where the public key is to be found, meaning there can be only one. The sparse Merkle Tree roots are put in a regular transparency log. That almost fixes it, but now how does a client monitor the list of keys being published on their behalf, to alert a user if an unexpected key appears?
It has to download the whole log, which is prohibitive. Enter SEEMless, which in the abstract is a mechanism to ensure that the sparse Merkle Tree contains the history of every past public key for a certain phone number. There still needs to be an auditor that checks that this append only property is maintained across trees roots, but at least that can be one (or a few) third-parties keeping the publisher honest, freeing each client from doing it themselves.
What about privacy? CONIKS uses Verifiable Random Functions for that. They are like hashes, but to generate them you need a private key (like HMAC), and there’s a per-hash key you can use to verify they were correctly computed (unlike HMAC). That means only WhatsApp can hash phone numbers into Merkle Tree coordinates, but they can also give you a proof that they generated a hash honestly so you know that’s the right spot to look at. I love VRFs, and they can actually be very simple if you make yourself the favor of using a prime-order group like Ristretto.
There is significant overlap between the two talks “WhatsApp Key Transparency” by Lawlor and Lewi of WhatsApp and “Key transparency: introduction, recent results, and open problems” by Melissa Chase of Microsoft, because they both present CONIKS and SEEMless. The former is from the point of view of the team that deployed them (in prod!) for WhatsApp, the latter from the point of view of one of the researchers involved in writing the SEEMless paper.
The WhatsApp talk presents the concept of KT and the CONIKS/SEEMless strategy, and then goes into the details of how their server infrastructure and storage backend manages the load, as well as how the client UX looks like. A fascinating side-effect of requiring public monitoring is that KT leaks interesting metrics such as the rate of user (re-)registration. Looks like WhatsApp sees around 300/s. They share their open source Rust implementation, AKD, and mention it can be used to verify the append-only audit proofs.
Chase’s talk is a methodical step through the various iterations of KT, looking at the mechanism and shortcomings of each and how those are addressed by the next. I found the open questions section especially interesting. Two in particular point to what I think are missing pieces in this picture:
- What happens if a user doesn’t come back online to monitor?
IMHO, clients should provide an option to export the VRF of your own phone number, so you can sign up for third-party services that alert you when new keys are published, so you don’t need to keep using WhatsApp to keep monitoring it.
- How do we instantiate the bulletin board?
“Bulletin board” is a term of art for a magic append-only list with a global view, where the sparse Merkle Tree roots are published. It needs to be impossible to hide entries because it’s how auditors check the append-only properties of the log and how monitors check the latest entries. Does that remind you of anything? It’s the tlog abstraction I talk about in my talk, and the witness network we are working on building solves this exact problem!
WhatsApp’s solution in the interim is fun: they made an AWS S3 bucket and turned on the option for legal retention where AWS promises contractually to never let you remove entries. It’s a pretty creative solution.
Privacy enhancing technologies
Written by: Aleksandar Kircanski
Anonymous credentials
For the development of efficient Anonymous Credentials: video.
zk-creds: Flexible Anonymous Credentials from zkSNARKs and Existing Identity Infrastructure: slides, video.
In today’s world, large companies handle user identities across the Internet. The UX (and security) benefits of the “Log in with Google” button are too good of a sell for users to not be used; this results in a privacy issue where a single company gets to track user activity across independent and unrelated domains. It is also a single-point of failure, as the user is not in full control of their own identity.
For a broader perspective on user identity on the Internet, see this blog post, which chronicles how the notion of identity on the Internet evolved over time. From the privacy perspective, the notion of self-sovereign identity is put forward. A self-sovereign identity could be implemented using private/public key pairs, stored for example, in hardware devices. These keys can be attested by 3rd parties that vouch for certain aspects of user identity and credentials, such as “Alice is over 21”. For how this could fit in the web authentication story, see for example, this discussion.
A number of privacy questions springs up if a credential is represented as a private/public key that the user controls. First, there’s the question whether it’s possible to extract and present just a subset of credential claims (Alice is over 21 vs. Alice’s exact age). This is actually similar to the consent part of the OAuth workflow. Another question is whether colluding servers and/or the issuing party can link the user’s credential presentations, even if they’re in collusion.
Questions like that fall under the category of anonymous credentials research. This field was initiated by David Chaum in 1984 and the next development was the CL signature scheme by Jan Camenisch and Anna Lysyanskaya, who received the Levchin prize for work in this area at RWC 2024. The CL signature operates in the RSA setting; as for a scheme based on elliptic curve pairings, see the BBS signature scheme from 2004.
At RWC 2024, Michael Rosenberg, Jacob White, Christina Garman and Ian Miers presented an anonymous credential construction based on the general purpose zero-knowledge proofs. They argued that while bespoke constructions such as the ones based on CL and BBS signatures are more efficient, they’re less generic and less extendable by non-cryptographic audiences. This work posits that it makes sense to rely on a general purpose and ubiquitous technology such as ZK-Snarks, trading efficiency for modularity and ease of use.
Your phone call privacy (STIR/SHAKEN)
STIR/SHAKEN is a suite of protocols aiming to mitigate robocalls by curtailing caller ID spoofing. It’s a technology analogous to email’s DomainKeys Identified Mail DKIM, which is used to fight email spam. In both protocols, it’s not the original caller/sender who signs the message; it’s the first network intermediary that signs the message. In the case of email, that’s the SMTP server on the email route and in the case of STIR/SHAKEN, that’s the first calling infrastructure provider.
Clearly, this means there’s no firm binding between the caller identity and their message/call. Nonetheless, the signature passed as part of metadata still helps to fight origin spoofing, as the attesting intermediary has means of verifying the origin and, assuming honesty, will not sign incorrect statements. As for dishonest intermediaries, the signature can act as a proof of misconduct. As of Feb 2024, 37% of calls run STIR/SHAKEN.
The STIR/SHAKEN: A Looming Privacy Disaster talk by Josh Brown and Paul Grubbs point out that STIR/SHAKEN does not satisfy privacy requirements that would be expected from a modern protocol. The talk is not about vulnerabilities or exploits against the protocol or the network, it’s about privacy issues that ultimately affect end-user security.
For example, caller ID information is shared with a number of off-path services as calls traverse throughout potentially diverse and legacy networks. Also, call logs now contain non-repudiable caller IDs; in the case of call data leaks, the call data can be validated by the STIR/SHAKEN cryptographic evidence. Here, the analogy with DKIM extends well; see these real-world examples of a real-world effect of non-repudiability, as well as this blog post. The authors of this talk are working on making the protocol better by using well known cryptographic primitives such as blind signing and deniable signatures. If these improvements are adopted down the line, this would be a big win for caller privacy on the overall.
Obfuscated key exchange
Shannon Veitch presented work on key exchange in the context of censorship circumvention technologies. More precisely, this is in the context of the ongoing arms race between censoring Internet traffic and censorship circumvention tools; even if from 2016, this survey is a good introduction as to what the “arms” look like. As for the circumvention tools, there are several methods, including:
- Tunneling traffic through an “allowed” protocol. Any VPN over TLS can be considered to be in this category. Now, most of the VPN solutions out there do not attempt to mimic a “typical” browser TLS session and are therefore inadequate. As with other techniques in this domain, side-channels are a very difficult problem to deal with. Check for example, this paper on meek side-channel resistance.
- Fully Encrypted Protocols (FEPs). FEPs aim to remove any recognizable protocol metadata based on which censoring may be applied. The idea is to fully encrypt the protocol using a pre-shared key. FEPs require that the censor does their job by blacklisting; if the censor drops protocols they don’t recognize, FEP traffic will be dropped as well.
The Obfuscated Key Exchange RWC talk focuses on the key exchange aspect of FEPs specifically, models them in a cryptographic framework and also discusses them in terms of post-quantum security.
Post-quantum messaging
Written by: Iago Passos
Designing iMessage PQ3: Quantum-secure messaging at scale
Slides not available, video.
By now you’ll have noticed that the structure of this blog post is more of an overview and highlight into specific talks that got our attention, since for most talks you can check out the papers they’re based on, download their slides on the RWC 2024 program page, and even watch talk videos. However, for the iMessage PQ3 talk from Apple, you can watch the PQ3 talk video but you can’t get the PQ3 talk’s slides. So let’s look at some of my notes:
Post quantum crypto is important, because quantum computing is developing fast… yadda, yadda, yadda… Apple needs to release an update to the iMessage protocol so it is protected against harvest now decrypt later attacks, when a cryptographically relevant quantum computer decides to grace us with its presence.
I admit, it wasn’t said like that. But let’s be real for a moment here, if you take the paragraph above to free tier chatGPT and ask it to expand on it, it’ll probably spit out a usable introduction to a post quantum cryptography paper. I cleaned up the rest of the notes, but we’ve all read this intro enough times, we know it by heart. Anyway, I digress.
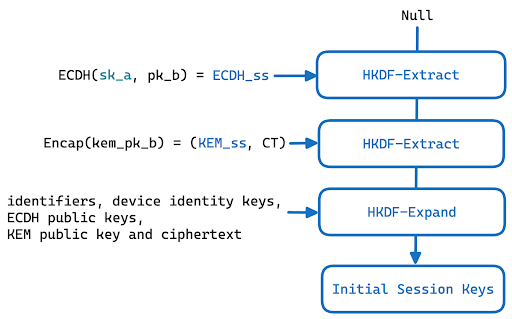
In order to make iMessage post quantum secure, when Alice wants to communicate with Bob, she requests Bob’s PQ3 Public Keys and Device Identity from the Apple Identity Services. This is a CONIKS key transparency scheme that is constructed as a Merkle prefix tree offering non-equivocation, guarantees of no spurious keys, privacy preserving consistency proofs and more. The Device Identity is also signed by the Contact Key Verification Account key, which guarantees that users can verify that they’re correctly gauging each other’s public keys.
The device identity is given by:
message DeviceIdentity { required bytes p256SigningIdentity; required uint32 pq3Version; }The PQ3 public keys are given by an ml-kem public key, a p256 public key, a timestamp and the pq3 registration signature. The addition being the ml-kem:
message PQ3PublicKeys { required bytes mlKEM1024PublicKey; required bytes p256PublicKey; required double timestamp; required bytes pq3RegistrationSignature; }With that the initial sessions keys are then derived from:
The HKDF is built from SHA384. Then we get to the asymmetric ratchet.
Here are a few catches. The classical DH ratchet continues working as it did previously in iMessage, meaning one new ECDH with every response. However, the PQ part of the ratchet (in parenthesis in the image above) only happens when either one of these two conditions are met: a set number of DH steps take place (calculated so that it happens at about every 50 messages exchange, based on gathered data), or an undisclosed amount of time has passed (claimed to be at most 7 days, depending on network connectivity) since the last rekeying. This is designed to amortize the cost of the lengthy Kyber ciphertext, they even go to the point of doing the PQ ratchet with Kyber-768 rather than Kyber-1024 used when establishing the initial session keys.
PQ3 also uses the Padmé Padding to avoid leaking message size to a certain degree. Leakage is limited to
O(log log M)by a heuristic measurement of the maximum message length of M bits. The message key derived from the symmetric ratchet serves as input to a KDF to generate a 256 bit AES-CTR key, and a 128 bit IV. And the text contents are finally encrypted.So, the current state of affairs: to avoid the Harvest Now, Decrypt Later problem, the symmetric keys are being kept above 256 bits (iMessage used 128 bits for a long while, and later upgraded only certain users to 256 bit keys, now it’s universal), PQ cryptography guarantees long term confidentiality, but authentication remains reliant on classical cryptography.
The next step: post quantum authentication. It’s important to point out that a study with a security analysis of PQ3 was uploaded to IACR’s ePrint, and they also have a formal analysis via the Tamarin Prover on Apple’s website.
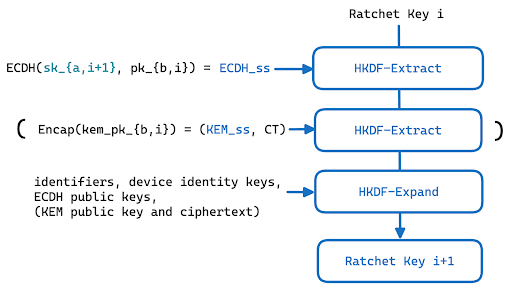
Signal has the same problem - but it’s not just non-interactive authentication, it’s plausibly deniable non-interactive authentication - so it’s a little more complicated. There are ways to solve it, for example, ring signatures or designated verifier signatures, it’s just not standardized and well researched at the moment.
An analysis of Signal Messenger’s PQXDH
Collaboration between researchers from Signal, INRIA, and Cryspen resulted in work with formal proofs for Signal’s PQXDH, with a focus on their developmental approach where the code follows the formal proofs. The first design of PQXDH allowed a man-in-the-middle through a KEM re-encapsulation vulnerability that was caught via symbolic analysis in ProVerif. Crypto engineers have become used to Diffie-Hellman properties in key exchange, while the reality is that key encapsulation allows re-encapsulation without breaking their IND-CCA claim. Thanks to the discovery, the design could be patched to tie in the public key of the recipient, preventing the adversary from spoofing the victims public key undetected. This can also be done in the key derivation step, but Signal chose to add the recipient’s public key as additional data in the AEAD scheme, which is a somewhat roundabout way to solve the issue.
Back to Apple’s PQ3 blog post, I turned my nose a bit to their classification of Signal as “Level 2” security while the almighty PQ3 is a “Level 3”. Their classification being Level 2 -> PQKX, Level 3 -> PQKX + PQC rekeying and Level 4 -> PQKX + PQC rekeying + PQC authentication). These claims were not repeated during the conference perhaps because, as Filippo put it, “store now, steal a key later, decrypt in fifty years is not a very compelling attack scenario”. I do appreciate however, that the PQ public key on PQ3 is tied on the KDF, rather than as the additional data of the AEAD that Signal went for, it feels spaghetti-like. PQ3 deals with the issue right where it was created, which has been my approach in the past, and it makes for a more clean and reusable construction. I’m not comfortable declaring iMessage above Signal on PQ at this point. Signal seems more worried with PQC deniable authentication now, and rekeying seems trivial compared to it.
Swoosh: Efficient lattice-based non-interactive key exchange
In the PQ implementations part of the conference was
Swoosh, one of the non-interactive key
exchanges that was hoping to solve some of the issues Signal and iMessage are
having with PQ. An interesting proposal, with great performance, faster than
CSIDH. However, two weeks after the conference a
quantum algorithm for solving LWE
problems was published on IACR’s ePrint, and the post-quantum future of Swoosh
is up in the air.** If the attack is proven correct, it’s likely that Swoosh
is not post quantum secure, as well as a good chunk of FHE schemes, and who
knows what more. Being fair, the whole PQ scene is in suspension waiting for a
response to this paper. Especially considering that an improvement on this
quantum algorithm could also spell disaster for Kyber and Dilithium, the most
prominent NIST standardization competition winners, and may prompt people to
look back at the contestants left back at the third round of NIST’s
competition.
As I was saying, Swoosh seems like a promising step towards helping Signal and PQ3 get the asynchronous deniable key exchange. Since most of the schemes depend on the existence of a PQ NIKE, and the scheme touted before, CSIDH, doesn’t seem to be that hot on cryptographers minds. This looks like a win to me.
Talks, talks and more talks
Before ending the blog post, let’s share notes for a couple more talks that don’t fit into a single topic.
Watermarks for language models: a cryptographic perspective
Section by: Iago Passos
The goal of this work is to separate AI generated content from human generated content. This is done by adding noise to AI responses that don’t affect response quality, but are verifiable. You can certainly start thinking about the N ways in which this would also fail, however the authors are quite aware of these issues. They model the limits of their approach and seeing the utter failure of post-hoc detection schemes, where you train another model to receive an input that could be AI generated and have it classify it, I was very eager to hear the proposal.
The talk focuses on LLMs, the naive approach is changing the probabilities of words based on a secret, or favoring certain words based on a secret. However, this approach makes it difficult to detect the watermark, and can also mess with the quality of the model. So the work is around four desired properties and defining them formally: Quality (ensuring the watermark doesn’t break the model), Soundness (low false positives), Completeness (make the watermark clear to detect) and Undetectability. Undetectability is the main advancement of this work, it claims to achieve full undetectability, which is a property that prevents an adversary from detecting the watermark to remove it.
The scheme is basically waiting for the responses to have enough entropy before injecting the watermark, consequence being that short responses won’t produce a watermark, but once a threshold entropy is reached, the watermark is inserted and proven undetectable. By breaking this strategy into various substrings that form the response, the proposed watermarking, in addition to the undetectability, also has substring completeness. This means that even if parts of the response are copy and pasted the watermark can still be detected.
What’s impressive is that this work seems to bypass an assumption that there is a trade-off between Quality and the robustness of the scheme against an attacker trying to detect/circumvent the watermark. This type of gain is rare in any mix of machine learning and cryptography.
Weak Fiat-Shamir attacks on modern proof systems
Section by: Aleksandar Kircanski
Before blockchain and zero-knowledge proofs, there were two good contestants in the “most complicated cryptographic protocol deployed in the real world” competition. One is Direct Anonymous Attestation which allows authentication while preserving privacy and is based on anonymous credentials. As mentioned in this paper from 2015: Direct Anonymous Attestation (DAA) is one of the most complex cryptographic algorithms that has been deployed in practice.
The other contestant is the voting protocols family. An example of an early open source voting protocol is the Helios voting protocol; this is important as it is a vulnerability in Helios that started off an avalanche of bugs in usages of Fiat-Shamir.
One of commonly used techniques in the area of ZKPs is the Fiat-Shamir heuristic, which transforms an interactive protocol to a non-interactive one. Grossly over-simplifying, in interactive versions of the protocol, the challenger generates a random challenge to which the verifier responds. Fiat-Shamir replaces this random nonce with a hash of the previously processed messages.
It turns out that Fiat-Shamir is easy to get wrong by not including certain seemingly unimportant parameters during the hashing process. Quang Dao presented a talk that essentially swept through most of the ZKP implementations, looking for weak Fiat-Shamir issues. As such, this work provided a lot of value to the community. This area is (hopefully) no longer a mess. The corresponding paper can be found here.
As mentioned, it is interesting that the attack was initially discovered in a paper that analyzed the Helios voting system. Mind your voting protocol attacks, as they may re-appear in other (very complicated) cryptographic protocols!
Video-based cryptanalysis
Section by: Iago Passos
Side channels are just annoying. The greatest defense the cryptographer has against side channels is “it’s not on the threat model”, which is very little. The time I had in this area has led me to conclude that the only way out is specialized hardware, and you still have to hide yourself well behind your threat model. There isn’t a healthy amount of sleep where the question “what if my adversary has a super precise electromagnetic probe that can sample at 1GHz rate?” leads you. But to further our paranoia, we had a talk on video based cryptanalysis, where photodiodes were used to measure the intensity of the LED of a cellphone while it does a key exchange to recover the keys. The attack was expanded to use video cameras, and later using the rolling shutter function of the iPhone to compensate for the slower sampling of the recording.
Given my previous bout with SCA, this is not surprising. But impressive to see published, and more impressive yet to find that measuring the LED of a speaker connected to the same power outlet as a charging phone doing the key exchange also allows for the key recovery. Again, not unexpected, by this point the attacker has access to the power outlet the victim is using to charge their phone, a side channel threat model here would allow for much more aggressive probing. But still, it’s bewildering to think about how cheap this attack has become. A camera to record a specially placed equipment with an LED, and a victim looking for a power outlet to charge their phone, and it’s a done deal. It’s hard to get cheaper than this with this little access. The presenter was also memorable - by the end challenging people from the intelligence services to reveal how long they have known about this. You have to love cryptography for being one of the few fields that can measure up to their romanticized depictions in cinema and books.
This is probably my top 2 favorite SCA paper. The first one is from this squad here, who were obviously not using their Air Force research budget to develop Counter Strike cheats and happened to find they can recover keys using the open microphones of people on Discord. Also, here is a fun two minute paper video on research about another video-based, romanticized exploit from 8 years ago.